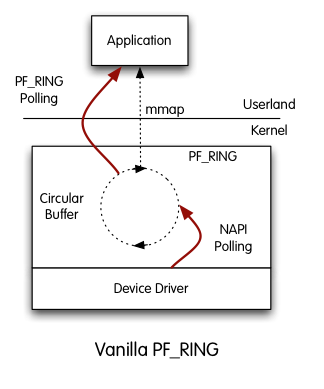
- 适用于Linux内核2.6.32及更高版本。
- 无需修补内核:只需加载内核模块。
- 使用商用网络适配器的10 Gbit硬件数据包过滤
 用户空间ZC(新一代DNA,Direct NIC Access,直接NIC访问)驱动程序可实现极高的数据包捕获/传输速度,这是因为NIC NPU(网络处理单元)在没有任何内核干预的情况下将数据包从用户域推送/获取数据包。使用10Gbit ZC驱动程序,您可以以线速发送或接收任何大小的数据包。
用户空间ZC(新一代DNA,Direct NIC Access,直接NIC访问)驱动程序可实现极高的数据包捕获/传输速度,这是因为NIC NPU(网络处理单元)在没有任何内核干预的情况下将数据包从用户域推送/获取数据包。使用10Gbit ZC驱动程序,您可以以线速发送或接收任何大小的数据包。- PF_RING ZC库,用于在线程、应用程序、虚拟机之间以零拷贝分发数据包。
- 设备驱动程序独立。
- 支持Accolade,Exablaze,Endace,Fiberblaze,Inveatech,Mellanox,Myricom / CSPI,Napatech,Netcope和Intel(ZC)网络适配器。
- 基于内核的数据包捕获和采样。
- Libpcap支持(请参见下文)可与现有的基于pcap的应用程序无缝集成。
- 除BPF外,还可以指定数百个标题过滤器。
- 内容检查,以便仅通过与有效负载过滤器匹配的数据包。
- PF_RING™插件,用于高级数据包解析和内容过滤。