在本系列的第一篇文章(第1部分)中,我们描述了如何使用n2disk和PF_RING构建2×10 Gbit连续数据包记录器,在第二篇文章(第2部分)中,我们描述了从10 Gbit扩展到100 Gbit所需的硬件。吉比特 现在已经过去了一年,我们在100 Gbit记录方面积累了更多的经验,现在该刷新以前的文章并分享有关新捕获和存储技术和配置的更多信息,以便构建能够转储100+ Gbit线速小数据包持续流量的记录器。
对于那些第一次阅读此主题的人来说,连续数据包记录器是一种连续捕获原始流量到磁盘的设备,类似于CVR摄像机,它提供了进入网络历史记录的窗口。这样,无论何时发生网络事件,您都可以及时回溯并分析直到原始数据包出现在网络上的流量(包括标头和有效负载),以查找导致具体问题的确切原因。
使用ntop的套件中的n2disk,可以构建这样的设备并使用标准PCAP格式转储流量。此外,通过利用PF_RING加速,n2disk能够捕获,索引和转储来自1/10/100 Gbit链路的流量,而在任何流量情况下都不会丢失数据包。今年,我们发布了一个新的 n2disk 稳定版3.4,除了添加了一些有趣的功能(包括基于L7应用协议过滤流量的功能)之外,还在基于FPGA的NIC上运行时引入了主要的性能优化。
在本文中,我们将重点介绍100 Gbit记录,描述用户在生产环境中成功使用的硬件和软件配置。
硬件规格
网卡
如前一篇文章中所讨论的,由于PF_RING 模块提供了抽象层,因此n2disk能够捕获来自许多适配器的流量。根据我们需要的速度和功能(以及我们的预算),我们可以决定购买商品适配器(例如Intel)或专用FPGA适配器(例如Napatech,Silicom / Fiberblaze)。
市场上有一些具有100 Gbit连接能力的商品适配器,但是,在将流量转储到磁盘上时,即使使用加速驱动程序,它们通常也无法在任何流量条件下(例如小数据包)应付全部100 Gbit吞吐量。主要原因是在这种情况下,我们无法使用RSS之类的技术来将负载分散到多个流中,因为这会将数据包(来自不同流的数据包)混洗到磁盘上,而我们需要保留数据包顺序以提供网络事件的证据。请注意,如果我们有一种对数据包进行排序的方式(例如,高精度的硬件时间戳),使用多流仍然是一种选择,而对于商品适配器来说通常不是这种情况。
FPGA适配器支持大块移动数据包,为像n2disk这样的应用提供高吞吐量,而在大多数情况下无需使用多个流(根据我们的经验,n2disk能够通过单个流处理高达约50 Gbps)。在本文中,我们将使用Napatech NT200A02适配器作为配置参考,但是也支持其他选项,例如Silicom / Fiberblaze。
存储
说到选择快速存储时,“Raid”这个词立即浮现在我们的脑海。一个好的Raid控制器(例如,带有2 GB的板载缓冲区)和一个Raid 0配置中的几个磁盘可以将I / O吞吐量提高到40+ Gbps以上。但是,这不足以处理100 Gbps。如果我们需要相当长的数据保留时间,并且机架空间不是问题,则可以使用几个Raid控制器和许多HDD或SSD磁盘来分配负载并达到所需的吞吐量。
更好的选择是使用NVMe磁盘。这些磁盘是直接连接到PCIe总线上的快速SSD。由于它们速度很快,因此它们甚至都不需要Raid控制器(实际上标准的SATA / SAS控制器无法驱动它们),并且可以利用n2disk的多线程转储功能来直接并行写入其中许多磁盘,大幅提高转储吞吐量。
我们使用P4500 / P4600系列的Intel NVMe磁盘,使用n2disk可以实现的吞吐量约为每个磁盘20 Gbps。这意味着8个磁盘足以记录100 Gbps的流量。请务必选择写密集型磁盘,保证足够的续航时间。
CPU
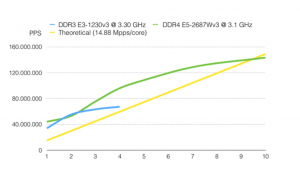
FPGA适配器能够在硬件中聚合流量,并在多个流之间分配负载。如前所述,n2disk可以通过单个捕获线程/内核和单个数据流来处理高达50 Gbps的速度。如果我们使用3+ Ghz Xeon Gold CPU,在50 Gbps的情况下,n2disk需要3/4个内核来索引流量。将流量转储到磁盘的线程需要一个以上的内核,总共需要6个内核。
如果要处理100 Gbps流量,则应使用2个流,每个流具有一个n2disk实例,因此需要3+ Ghz Xeon Gold(至少12个内核)。以最低速度要求以Intel Xeon Gold 6246为例。如果您要使用NUMA系统(多CPU),请注意前面文章提到的CPU亲和性!还请确保为系统配置足够的内存模块,以使用所有内存通道(请查看CPU规格)和最大支持的频率。
软件配置
数据流配置
[System] TimestampFormat = PCAP_NS [Adapter0] HostBufferSegmentSizeRx = 4 HostBuffersRx = [4,128,0] MaxFrameSize = 1518 PacketDescriptor = PCAP
如果一个数据流就足够了,则不需要额外的配置,因为可以直接从接口捕获(例如,端口0的nt: 0)。如果单个数据流不够用,因为流量吞吐量超过50 Gbps,则需要使用ntpl工具配置多个流,如下例所示。在下面的示例中,使用5元组哈希函数将流量负载均衡到两个流。可以通过捕获nt:stream (例如,流0的nt:stream0)来选择每个流。
/opt/napatech3/bin/ntpl -e "Delete=All" /opt/napatech3/bin/ntpl -e "HashMode = Hash5TupleSorted" /opt/napatech3/bin/ntpl -e "Setup[NUMANode=0]=Streamid==(0..1)" /opt/napatech3/bin/ntpl -e "Assign[streamid=(0..1)] = All"
n2disk配置
为了达到最佳的转储性能,一个好的n2disk设置也非常重要。《n2disk用户指南》的tuning部分包含有关正确配置dump设置,CPU核心亲和性,索引等的基本指南。
在下面示例中,我们通过两个n2disk实例捕获100 Gbps流量,分为两个流,每个流应处理50Gbps的最大吞吐量。流量以PCAP文件的形式存储在多个NVMe磁盘上,以循环方式进行。如前所述,每个NVMe磁盘的最大持续IO吞吐量为20 Gbps,因此每个n2disk实例将使用4个磁盘。
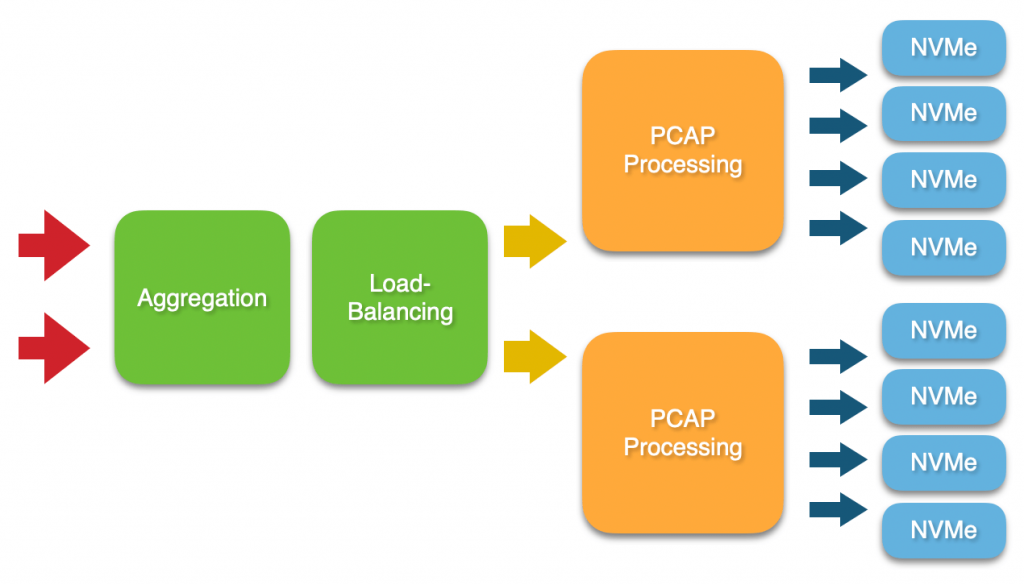
请注意,通过在npcapextract提取工具中选择n2disk实例生成的所有时间线作为数据源,以后可以从所有NVMe磁盘上无缝提取转储的流量。请在下面找到第一个n2disk实例的配置文件,并附上一些注释,描述每个实例应该做什么。
# Capture interface -i=nt:stream0 # Disk space limit --disk-limit=80% # Storages (NVMe disks 1, 2, 3, 4) -o=/storage1 -o=/storage2 -o=/storage3 -o=/storage4 # Max PCAP file size -p=2048 # In-memory buffer size -b=16384 # Chunk size -C=16384 # Index and timeline -A=/storage1 -I -Z # Capture thread core affinity -c=0 # Writer thread core affinity -w=22,22,22,22 # Indexing threads core affinity -z=4,6,8,10
下面请看第二个n2disk实例的配置文件,与上一个实例类似。在这里重要的是要注意CPU亲和性,以避免两次使用相同的内核(包括使用超线程的逻辑内核)影响性能。
-i=nt:stream1 --disk-limit=80% -o=/storage5 -o=/storage6 -o=/storage7 -o=/storage8 -p=2048 -b=16384 -C=16384 -A=/storage5 -I -Z -c=2 -w=46,46,46,46 -z=12,14,16,18
至此,我们准备启动两个n2disk实例。下图显示了连续捕获、索引和转储持续的100 Gbps流量(64字节数据包)时的CPU内核利用率。

现在,您具备了构建100 Gbps流量记录器的所有要素。
本文摘自Ntop,写于2020年6月15日